1.何謂Prometheus?
- 作為高度動態容器環境下的監控工具
- 如Kubernetes,Docker Swarm…etc
- 但是也可以應用在傳統基礎設施(bare server)及其上的應用程式監控
- 而這幾年Prometheus成為容器與微服務的主要監控工具
2.在哪邊以及為何使用Prometheus?
- DevOps如今變得越來越複雜難以手動處理
- 也就越來越仰賴自動化
- 考量到我們有一狗票的Server
- 上面跑了很多容器化的應用程式
- 裡面有上百個Processes
- 並且是有互聯的(interconnected),如下圖所示

- 要維運上述的配置,並且要避免Down time是非常困難的
- 考量到機台數更多,甚至分散在各處
- 然後我們又沒有內部可觀測的視野去了解內部的狀態,諸如
- 1.硬體層的狀態
- 2.應用程式的狀態

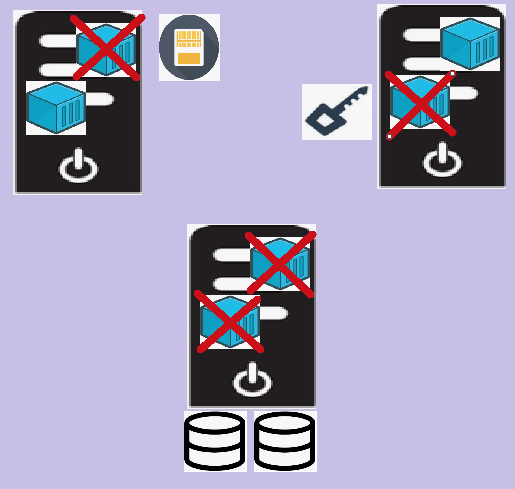
- 佈署的機台一多,當有某一台服務有異常,甚至連帶導致其他台服務的異常

- 如上圖即導致追查原因到修復的時間拉得很長
- 再另一種CASE,例如某個服務用光的Memory如下圖

- 這導致了該服務對應的容器被移除
- 而該服務又剛好是提供另兩個DB的容器應用同步資料的
- 這直接就造成了這兩個DB的容器應用也跟著掛掉

- 進一步地,有另一個驗證服務要透過上述DB的資料才能運作,也跟著掛
- 最後有一個依賴上述驗證服務的應用程式,可能只是個UI介面應用程式
- 由上述的原因,它沒辦法正常提供登入(需要驗證服務)的功能
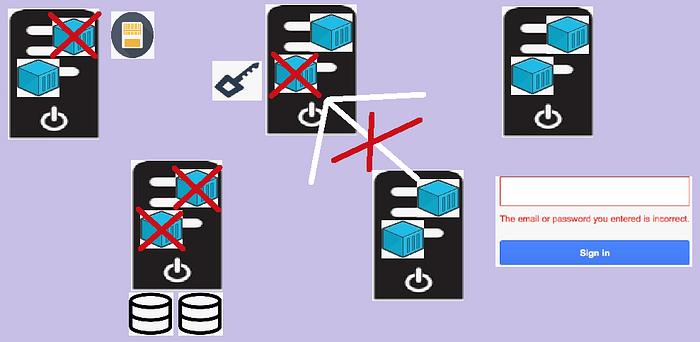
- 然後處理人員就不知道到底發生了什麼事
- 可能只看到認證異常等等錯誤,然後不曉得哪邊有問題
- 到底是哪個後端有問題?
- 哪邊有Exception?
- …逐一地查找問題才能鎖定問題根因並加以排除異常
- 而該如何更有效率地排查異常,就必須仰賴工具
- 常態地監控(constantly monitor)服務
- 當有crash時候發出alert
- 甚至在出錯誤之前,即顯示問題(例如Memory使用率已高過70%..etc)
- 又或者是logs不再增長(比如elastic search無法接收新的log)
- 可能是Server的disk已經滿載,或elastic search能存放的有受限制等狀況
- 我們可以設置條件來觸發alert例如儲存空間在50%的時候告警
- 又或著是某個APP服務反應變慢,可能是網路變慢,需要監控流量峰值
- 以上都是Prometheus可以提前做到alert的
3.Prometheus架構
- Prometheus到底如何運作?
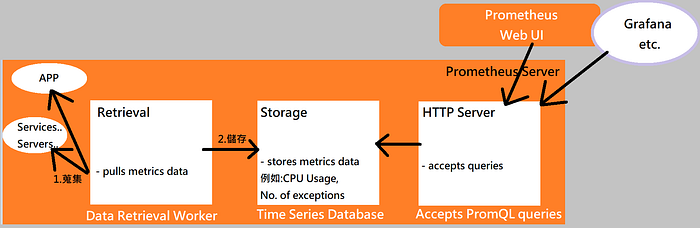
- 大致主體為Prometheus Server,主要目的就是監控
- 裡面有分三塊,架構大致如下,有Database與Retrieval
- 用以收集與儲存metrics

- 再來還有Web HTTP Server,會有Web UI介面顯示
- 也可提供其他UI如Grafana取得資訊使用
- 用以接受Query來去詢問Database查找的
Prometheus Server監控的目標(Targets & Metrics):
- Linux/Windows Server,Apache Server
- Single Application
- Service, like Database
- ...etc,上述Prometheus稱其為"Target"
- 而每一個Target內會包含許多"Units"來讓Prometheus進行監控
- Units例如:
- 機台本身相關的CPU Status
- Memory/Disk Space Usage
- 應用程式本身相關的Exception Count
- Request Count
- Request Duration
- 以上這些想要監控某個"Target"的某一個"Unit"即稱之為"Metric"
- 這些Metrics資料就會存放在Prometheus本身的Database裡面
Metrics:
- Format : Human-readable text-based
- Metrics entries會有:TYPE & Help attributes
- 其中Help主要是描述這個Metric是什麼
- TYPE則有三種不同的metrics種類
- 1.Counter : metric本身描述某狀況發生多少次
- 2.Gauge : 當下某數值是多少
- 3.Histogram(直方圖) : 多久或多大
接著還要談論Prometheus如何蒐集Targets的相關數據
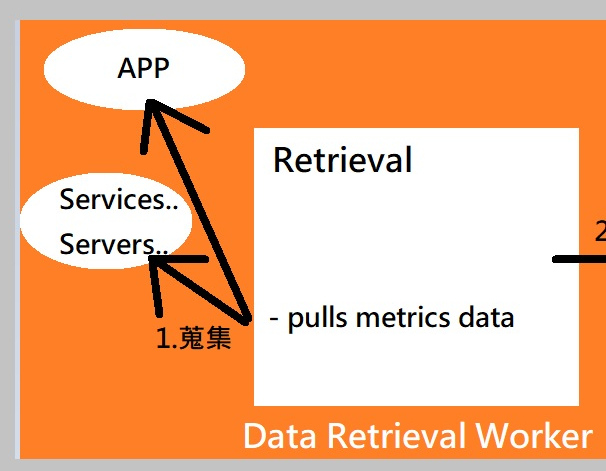
- 基本方式架構如下
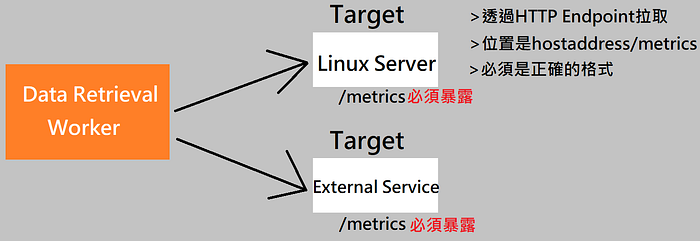
Target Endpoint and Exporters:
- 許多應用程式本身預設就有暴露/metrics這個Endpoint
- 其他應用程式沒有的就需要額外的元件 — Exporter
- Exporter可以是一個script或是Service並做以下事項:
- 1.Exporter會從Target中獲取Metrics
- 2.Exporter會將訊息轉換成合格的格式
- 3.Exporter在把訊息暴露在/metrics 這個Endpoint
- Prometheus官方本身就有一堆Exporter可以使用,例如
- MySQL的,Elastic Search的,Linux Server build tool的,Cloud Platform的..etc
- 舉例要監控一台Linux Server,則可以下載"node exporter"
- 把它untar做解壓縮並執行它
- 然後它就會轉換Server的metrics資料,並暴露/metrics這個Endpoint

- 然後設置Prometheus去搜刮這台Server的該Endpoint
- 並且這些Exporter同樣支援容器化的應用,例如在K8S內
- 有一個MySQL的容器Pod,可以在旁邊搞一個sidecar的Exporter容器
- 並協助MySQL傳遞其Metrics並暴露/metrics這個Endpoint資料給Prometheus,只要Prometheus有設置要蒐集的話
監控自己的應用程式:
- 多少requests?
- 多少exceptions?
- 多少Server的資源被使用?
- 這些都有對應各程式語言的Client Library可以使用
- 使用上述語言對應的Library就會自動暴露/metrics供給給Prometheus
拉取機制(Pull Mechamism):
- 前面有提到,Data Retrieval Worker會去各Target的/metrics端點抓資料
- 這是非常重要的特徵
- 其他的監控系統例如AWS的Cloud Watch,New Relic使用的是Push給集中的蒐集平台,也就是監控系統
- 所以假若我們有很多微服務系統,就要主動推送很多資料
- 這會造成高流量的問題(High Load of Network Traffic)
- 監控系統反而會成為瓶頸
- 這雖然監控運作也會不錯,但是就要花更多錢在負載去支撐常態的Push請求給監控
- 另外就是還要在各個Targets上安裝daemon來推送metrics資料
- 然後Prometheus只要去接收Endpoint就好
拉取式的系統是比較有優勢的:
- 尤其是在複數結構下的Prometheus實體機台來拉取資料
- 也更好地偵測服務是否運行中
- 例如Prometheus嘗試去pull時候沒有回應,或是Endpoint打不到
- 而服務本身又不push資料或傳遞本身health狀態等很多原因,即便服務本身並不是沒有運作中
- 有可能是網路問題,封包流失...等等問題
Prometheus的Pushgateway元件:
- 若是Target本身只運作一段很短的時間,導致Prometheus蒐集不到資料
- 像是批次或排程任務,清除資料,備份...etc
- Prometheus提供了Pushgateway元件
- 讓這類短時間存在的服務應用自己本身推送metrics
- 不過這種應該要當成比較例外的使用方式
- 因為如前面討論的透過Push方式就會有其問題存在
設定Prometheus:
- Prometheus如何知道去哪且何時蒐集資料?
- 這些全都寫在prometheus.yaml
- 裡面定義
- 1.哪個Target
- 2.間隔(interval)
- Prometheus會利用它自己本身的服務發現機制去找到Target Endpoint
- 當第一次安裝就會看到範例的預設設定檔

- 如上範例就有三個區塊
- 1.多久蒐集一次
- 2.如何整併數據或建立告警條件
- 3.去哪邊蒐集
- 另外Prometheus本身也自帶/metrics這個Endpoint
- 也就是自己監控自己本身的health狀態,如上圖localhost:9090就是
- 然後Prometheus就會自己抓自己的"localhost:9090/metrics"資料
- 當然也可以自己定義Job做監控:
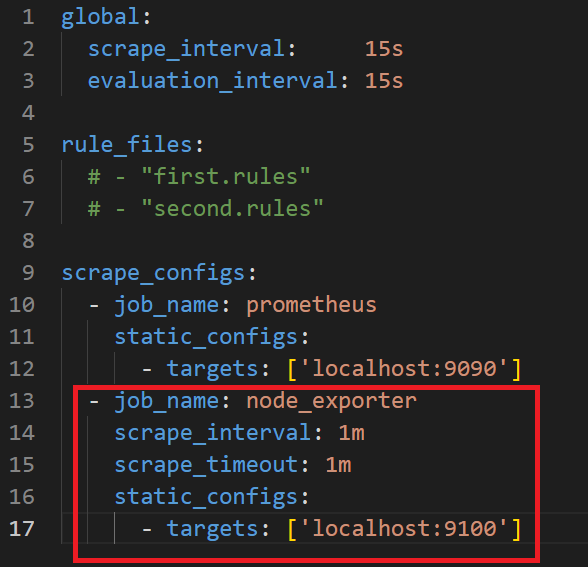
甚至可以調整:
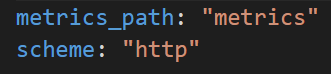
Alert Manager:
- Prometheus如何觸發告警(Alert)? →上面的rule
- 誰來收到告警?
- Prometheus有另一個元件叫"Alert Manager"
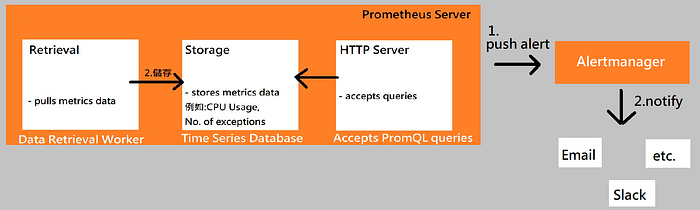
- Alert Manager專門用來發送給不同管道做告知
- Prometheus會依據config檔內設置的alert rule,然後觸發Alert的發送
Prometheus Data Storage:
- Prometheus在哪邊儲存資料?
- 用以存放蒐集來甚至整合過的資料,其實就是硬碟(可能地端/遠端都可)
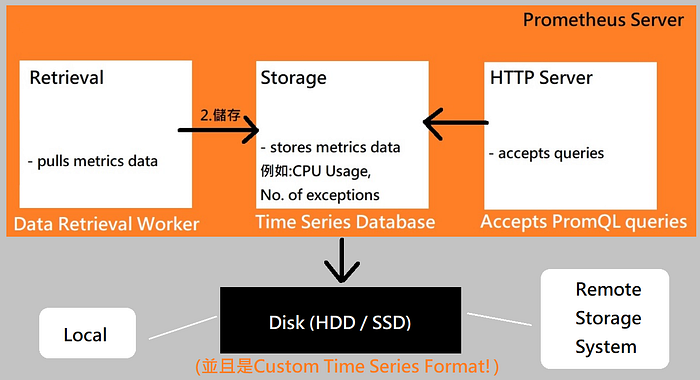
- 由於一定是"Custom Time Series Format"
- 所以也就不能直接地寫到RDB去
- 並且也提供上圖右邊的HTTP Server透過PromQL Query Language進行查詢
PromQL Query Language:
- 透過Prometheus的Web Server的Web UI介面
- 透過其PromQL語法進行查詢
- 或著可以使用更強的可視化工具 — Grafana
- Grafana同樣透過PromQL去撈取Prometheus資料做呈現
- 以下是範例的PromQL Query語法
#查找所有HTTP Status Code非4XX範圍的:
http_requests_total{status!~"4.."}#查詢過去30分鐘內,5分鐘的http請求的metrics總數比率:
rate(http_requests_total[5m])[30m:]
Prometheus的特徵:
- 設計成高可靠性(reliable)
- 例如其他系統發生停電狀況,而我們要透過數據進行診斷
- 所以Prometheus被設計為"stand-alone" & "self-containing"
- 亦即它本身並不依賴網路儲存空間或其他遠端服務
- 這意味著即便其他基礎設施掛了,它依然能夠運作
- 沒有其他額外建置的必要
- 但是這也反映著"Prometheus很難做擴展"
- 所以使用"single node"也就減少複雜性
- 但是能夠監控的量就有限
- 所以有必要的話就得增加Prometheus Server數量來擴增監控容量
- 否則只能限制監控的metrics來源數量了
透過Prometheus Federation來擴展Prometheus:
- 當我們擴展雲端應用時,監控能力也要跟著擴展
- 這時候就可以仰賴"Prometheus Federation"
- Prometheus Federation可以讓Prometheus Server去蒐集其他的Prometheus Server的資料
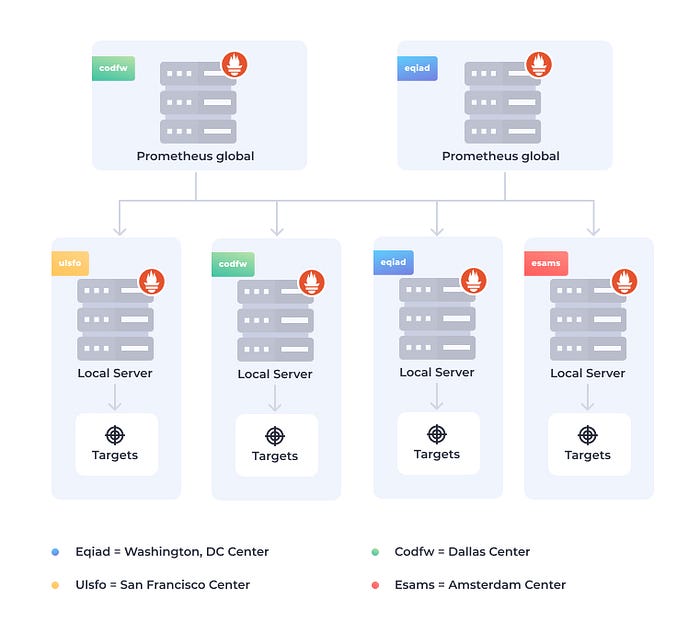
- 透過Prometheus Federation就可以達成Prometheus所需的擴展性
Prometheus與Docker與Kubernetes:
- 如最前面所述,這兩個平台都兼容
- Prometheus甚至被打包為Docker image
- 所以很容易地被佈署在容器化環境,例如Kubernetes
- 並且開箱即用(out-of-box)監控K8S叢集的資源
- 也就是一安裝在Kubernetes內就開始蒐集其資源數據,而不用另外設定
